

Inside the Computational Science Infrastructure Driving LLE’s Research
Much of the most important work at LLE happens not just in a lab but on a computer, where plasma behaviors are modeled, capsule implosions are tested, and the physics of extreme conditions are interrogated. Researchers simulate experiments as close to the actual experimental conditions as possible, but also have the ability to adjust parameters, explore edge cases, and probe regimes that current experiments cannot accommodate.
LLE’s capacity to simulate complex physical phenomena with high fidelity is one of its more powerful research capabilities—and one that is expanding. At the center of that capability is the High-Performance Computing (HPC) Group, a team within LLE’s Theory division that has built and continues to evolve a sophisticated scientific computing environment.

Simulation as a Scientific Instrument
Research at LLE has always depended on its instruments, including lasers, diagnostics, and target fabrication systems, which are each precision-engineered to reveal important information about the physics of extreme conditions. Computational simulation is an instrument in its own right and one that has for decades been central to experimental design. At LLE, simulations complement physical measurements, providing information that is not measurable in the lab. They allow researchers to see inside the physical problems and to understand not just what happened, but why, and what to explore next.
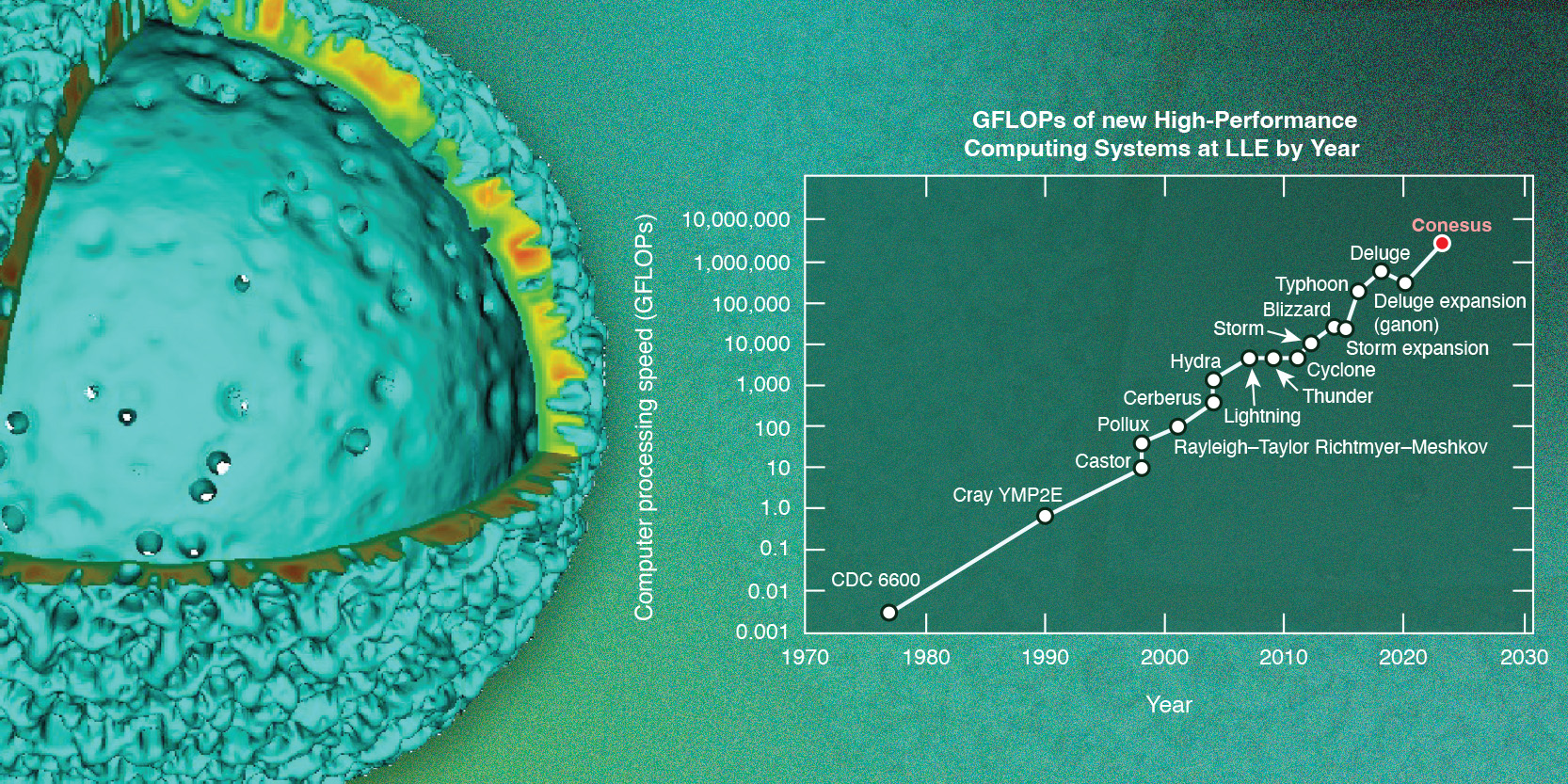
LLE’s computational science infrastructure currently serves more than 150 researchers across five LLE divisions, the University of Rochester’s mechanical engineering and physics and astronomy departments, as well as the Flash Center for Computational Science. Nearly half of these researchers are graduate, undergraduate, and even high school students who are developing skills in computation and computational methods, gaining through this work the ability to simulate some of the most complex physics on Earth. Training users on systems of this level of complexity is itself a significant undertaking, which is why the LLE HPC Group provides significant support in the form of documentation, hands-on training, and ongoing assistance that allows researchers at every level to work with confidence on the tools and codes they need. The range of what can now be explored computationally is growing, and LLE’s HPC resources like Conesus allow researchers to answer scientific questions in ways that were out of reach a decade ago.
The DOE/NNSA has consistently been a leader in bringing high-performance computing to the mission. NNSA’s Advanced Strategic Computing program, along with the ICF program, enabled LLE to acquire a new system, Conesus.

The Scale Required to Do This Work
High-fidelity simulations demand computing infrastructure at a large scale. LLE’s HPC Group currently operates approximately 800 individual computer units with 60,000 total CPU cores across four separate clusters. One cluster at LLE, Conesus, illustrates the magnitude of what this requires. At full capacity, it draws roughly 10 MWh of electricity per day—enough to power approximately 340 average American homes—and generates substantial heat that must be managed by sophisticated closed-circuit fluid-cooling systems. Despite this scale, Conesus ranked 77th on the Green500 list of the world’s most energy-efficient supercomputers, a recognition that reflects how seriously LLE approaches the responsibility of operating at this size. The University of Rochester’s computer center, where Conesus is housed, was purpose-built for machines like these and engineered to bear their weight, supply their power, and keep them cool.
Behind the computer processors sits an equally critical data infrastructure: petabyte-scale file servers capable of managing thousands of simultaneous read and write streams, ultrafast fiber networks connecting compute nodes, and redundant systems ensuring that when a simulation generates terabytes of data, nothing is lost. The computational instrument is only as good as its ability to capture what it produces.
Reliability as a Research Value
At the scale that LLE HPC operates, hardware and software failures are statistically inevitable. The HPC Group must not only recover from problems as they arise but also minimize their impact. The HPC infrastructure is built with redundancy throughout: multiple network paths between compute nodes, failover systems for critical services, continuous snapshots and backups of essential files, and long-term archiving for legacy data. Most issues are identified and resolved quietly, before they can affect a running simulation or delay a publication. For the researchers who depend on these systems around the clock, this invisibility is the point.
Equally invisible to most users is the software layer that makes the hardware usable. Every compute node runs an identical, carefully maintained operating system. On top of that sits a full stack of computational libraries, code compilers, debuggers, developer environments, and visualization tools—the instruments researchers use to write, test, run, and analyze their simulations. Automated job schedulers manage the flow of work across the cluster, balancing the demands of many users simultaneously while maintaining fairness and institutional priorities. Keeping all of this current, consistent, and compatible across hundreds of machines is a continuous undertaking, one that underpins every calculation that runs and allows researchers to trust that the environment will do what they expect. For science needing resources 24-7, reliability is itself a capability.
What Comes Next and Why It Matters
The computational frontier at LLE is moving fast, and the HPC Group is moving with it. The most immediate driver is scale: as simulations grow larger and more complex, the infrastructure to run and analyze them must keep pace. This means more CPUs, more memory, faster interconnects, and larger storage. At the same time, GPUs, chips originally designed for video rendering that have since become powerful tools in scientific computing, are becoming increasingly relevant for certain classes of large-scale simulation. GPUs are also highly valuable for artificial-intelligence and machine-learning (AI/ML) applications. LLE is currently procuring new, state-of-the-art GPU servers to accelerate the development of GPU-capable simulation codes and train new AI/ML models. The facilities that house these resources must also evolve to accommodate them.
Extracting meaning from the output of these simulations requires its own set of tools: from analysis software and post-processing pipelines to dedicated visualization servers capable of rendering large datasets in full 3D. These allow researchers to view and better understand the science behind what is happening in their simulations. Identifying trends from the increasingly large datasets of tomorrow will require more and more compute horsepower as well as fast storage and processing tools. What gets built next will be shaped by the scientific questions that LLE’s researchers are asking today, which will in turn shape what questions become answerable tomorrow.

Expanding the Edge of What’s Possible
LLE’s computational science capability is distinctive, not because of any single cluster or software stack but by the combination of scale, rigor, security, and foresight that allows researchers across the institution to do work that would otherwise be out of reach—as well as the steady effort to push that boundary further.
The simulations running today are more detailed, more accurate, and more revealing than anything possible five years ago. The researchers running them—the faculty pushing the boundaries of fusion theory and the students encountering the full scale of the problem for the first time—are the reason that progress occurs. In the Meliora spirit of “Ever Better,” the computational infrastructure at LLE is not something simply to be maintained and preserved. It is something to be built upon, year after year, in step with the scientists it serves.
Corresponding author: K. S. Anderson